Modern Data Engineering Milestones: Key Technologies That Shaped the Industry

In recent years, the field of data engineering has undergone significant transformations. Tools like dbt (data build tool) have emerged as vital components of modern data engineering workflows. These technologies not only optimize how data teams operate but also enable collaboration across diverse roles, including data engineers, analysts, project managers, and stakeholders. This article, based on my experience and a recent talk, explores how data engineering has evolved, why dbt has gained traction, and how it addresses pain points in data workflows.
The Rise of Modern Data Engineering
Five years ago, data engineering was still a niche role, often disconnected from general software development practices. At that time:
- Data engineering tasks were largely centered around managing and processing massive datasets, often from sources like APIs, product databases, or logs.
- Distributed storage systems like Hadoop were essential for handling these vast data volumes.
- Concepts such as unit testing for SQL queries, linting, or conventions were rarely applied in data workflows.
However, as data engineering matured, the need for more systematic, scalable, and collaborative approaches became apparent. This paved the way for tools like dbt, which integrates software engineering principles into data workflows.
What is dbt, and Why is it Revolutionary?
Enabling Cross-Role Collaboration
dbt’s primary purpose is to bridge the gap between data professionals and other stakeholders by providing a unified interface for understanding and developing data workflows. It enables users to:
- Trace the lineage of data tables and reports.
- Identify dependencies between tables, enabling quick troubleshooting.
- Generate comprehensive documentation that’s accessible to technical and non-technical team members.
For example, stakeholders can easily view the source tables for a report, understand its transformations, and identify the data’s origin. This level of transparency fosters collaboration and efficiency across teams.
Integrating Testing and Documentation
dbt ensures that data workflows are robust by:
- Integrating Testing: Users can define tests for individual fields, such as uniqueness or non-null constraints, directly within dbt configurations. These tests are executed automatically, providing immediate feedback on data quality.
- Generating Documentation: dbt auto-generates documentation based on the SQL logic and configurations provided. This documentation includes:
- Table definitions.
- Column descriptions.
- Test details.
The resulting documentation is displayed in an intuitive, web-based interface, making it accessible to all stakeholders.
Historical Context: Data Engineering Evolution
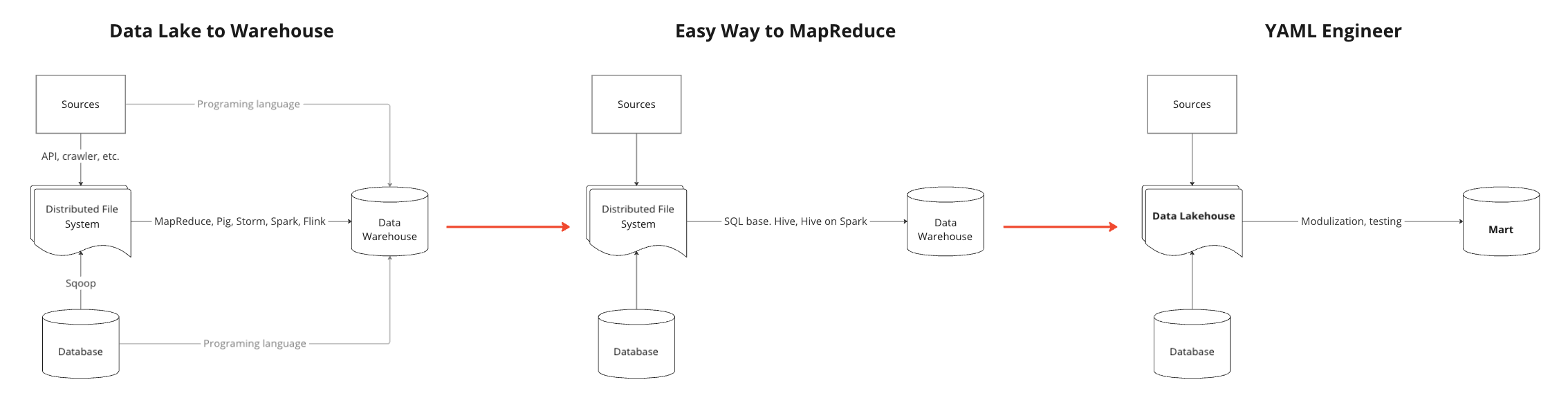
Traditional Practices
In the early stages of data engineering, the focus was primarily on handling raw data sources. These sources often required processing in distributed systems like Hadoop, where:
- Data engineers managed pipelines to integrate API, database, and log data into centralized storage.
- Practices like version control or modular development were less common.
Transition to Modern Practices
Over the past five years, the field has seen significant advancements:
- Adoption of Software Engineering Principles: Modern data engineering incorporates practices like unit testing, code linting, and standardized conventions for SQL development.
- Shift Towards Lakehouse Architectures: The industry has moved away from traditional data warehouses to lakehouse models, which decouple data storage and processing for better scalability and flexibility.
dbt in Practice: Features and Workflow
Data Lineage and Visualization
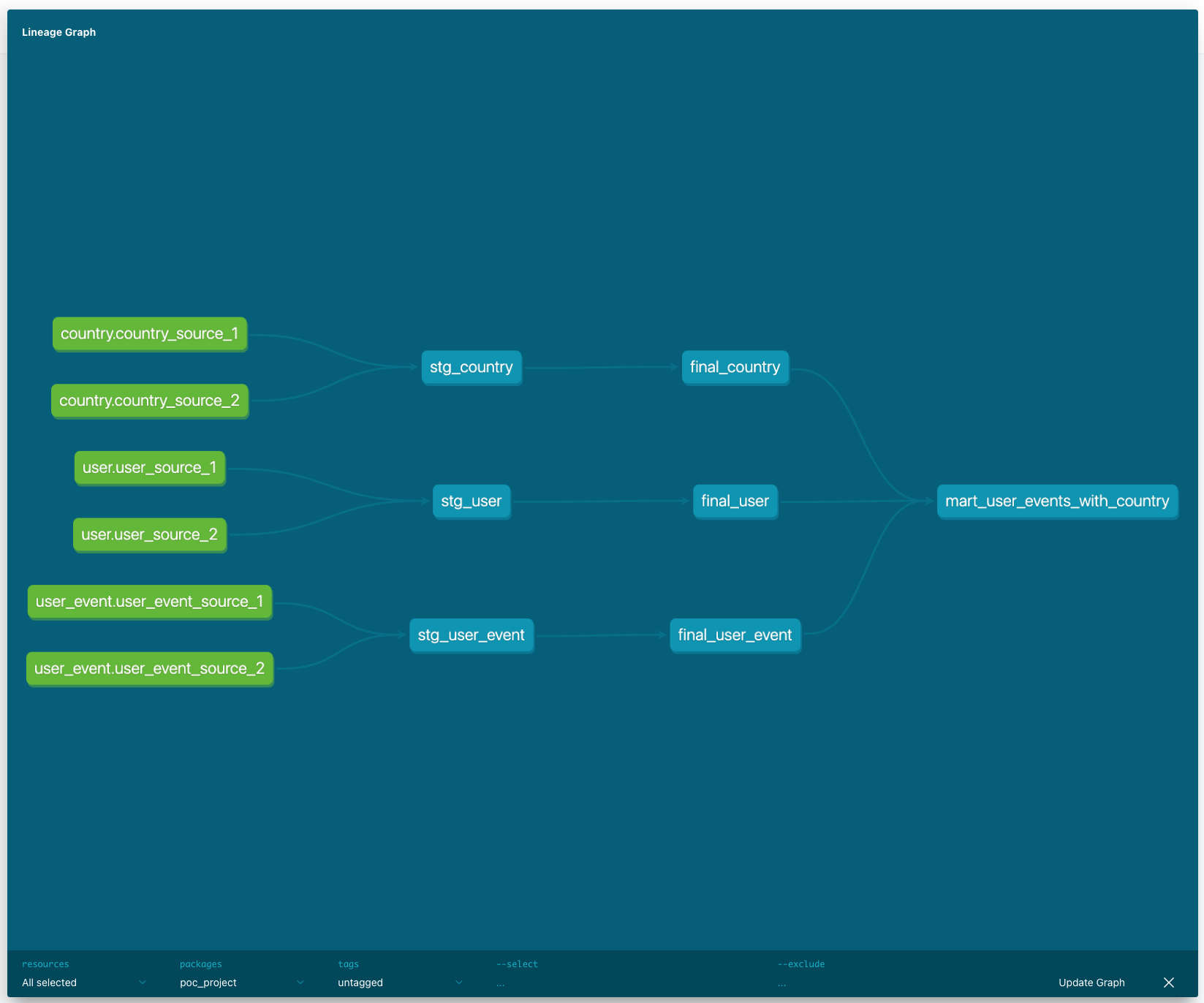
dbt excels at visualizing data lineage. Consider a use case where a data team wants to understand how a user_dashboard table is constructed:
- Source Tables: dbt highlights the raw data sources (e.g., logs, databases).
- Transformations: Intermediate tables and their transformation logic are clearly displayed.
- Final Outputs: Dashboards and reports are mapped back to their underlying tables.
This visibility ensures that everyone, from data engineers to project managers, can trace the origins and transformations of key datasets.
Modularity and Scalability
dbt promotes modular development through its modeling layer:
- Raw data is first transformed into an Operational Data Store (ODS).
- Intermediate tables (e.g., dimensions) are created to consolidate and enrich data.
- Finally, specific tables are built for different business units, stored in Mart schemas.
This layered approach makes it easier to scale workflows while maintaining clarity.
Execution and Testing
dbt supports command-line operations to build and test models. For example:
dbt runbuilds tables based on defined configurations.dbt testexecutes tests for individual or multiple tables.
A simple table configuration:
models:
- name: table_name
description: "Something something something..."
columns:
- name: user_id
description: "User identifier"
data_tests:
- not_null
- unique
- relationships:
to: ref('some_ref_table')
field: user_id
These operations can target specific tables or pipelines, optimizing performance and resource usage.
Industry Adoption and Use Cases
dbt has been widely adopted by companies across industries. Some notable examples include:
- Airbnb: With over 50,000 metrics, Airbnb uses dbt alongside AI to manage their complex data ecosystem.
- Dcard: Dcard mandates that its analysts use dbt for SQL development, highlighting its versatility beyond traditional engineering roles.
Other adopters like Gymnasium Education and Facebook have also reported significant gains in productivity and collaboration through dbt.
Challenges and Future Directions
While dbt has transformed data engineering, there are areas for improvement:
- Resource Management: Running
dbt runordbt teston large projects can be resource-intensive. Future enhancements might focus on better optimization and incremental runs.
Looking ahead, companies like Airbnb are exploring AI-driven tools to complement dbt, such as automatically generating SQL queries or identifying metrics based on natural language input.
Conclusion
The rise of dbt marks a pivotal moment in data engineering, emphasizing collaboration, transparency, and systematic workflows. By integrating software engineering principles into data practices, dbt enables data teams to deliver high-quality datasets and insights at scale. As the industry continues to evolve, tools like dbt will play an increasingly central role in shaping the future of data engineering.
For teams embarking on their dbt journey, understanding its history and features is the first step toward unlocking its potential. Whether you're a data engineer, analyst, or stakeholder, dbt empowers you to navigate and contribute to modern data ecosystems with confidence.