PandaSQL
Preset
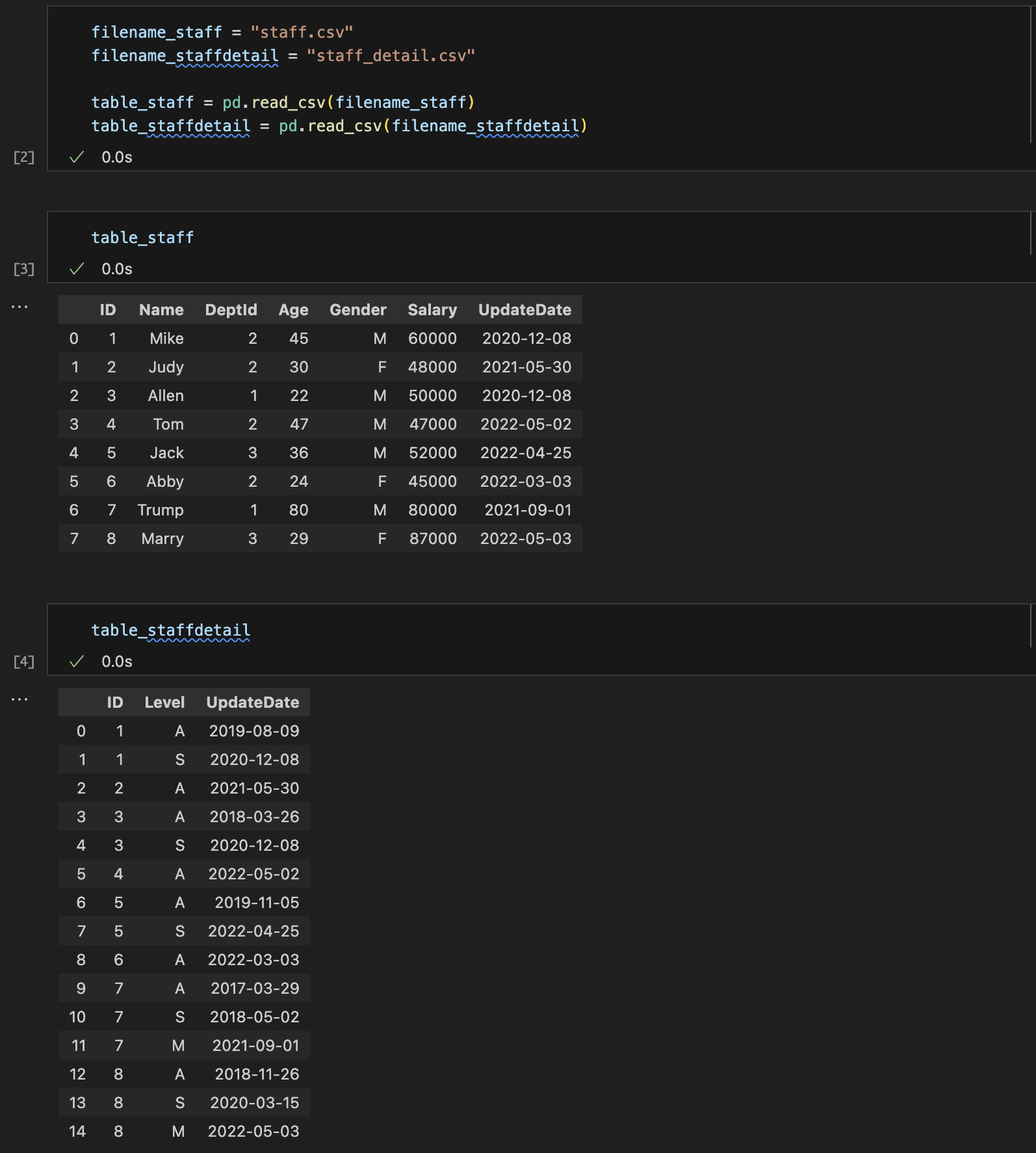
Create CSV files
staff.csv
ID,Name,DeptId,Age,Gender,Salary,UpdateDate
001,Mike,002,45,M,60000,2020-12-08
002,Judy,002,30,F,48000,2021-05-30
003,Allen,001,22,M,50000,2020-12-08
004,Tom,002,47,M,47000,2022-05-02
005,Jack,003,36,M,52000,2022-04-25
006,Abby,002,24,F,45000,2022-03-03
007,Trump,001,80,M,80000,2021-09-01
008,Marry,003,29,F,87000,2022-05-03
staff_detail.csv
ID,Level,UpdateDate
001,A,2019-08-09
001,S,2020-12-08
002,A,2021-05-30
003,A,2018-03-26
003,S,2020-12-08
004,A,2022-05-02
005,A,2019-11-05
005,S,2022-04-25
006,A,2022-03-03
007,A,2017-03-29
007,S,2018-05-02
007,M,2021-09-01
008,A,2018-11-26
008,S,2020-03-15
008,M,2022-05-03
Install and import packages
pip install pandasql

pandasql.sqldf
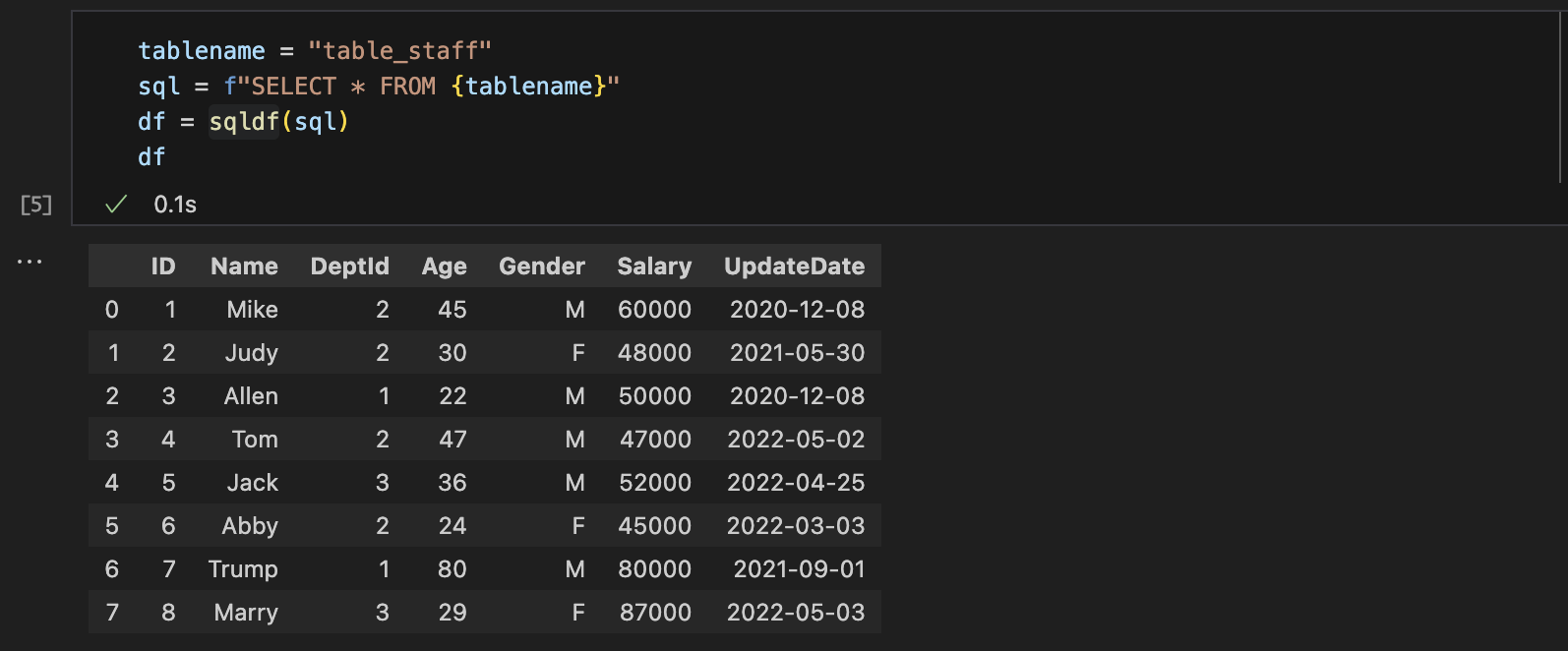
Read CSV as DataFeame
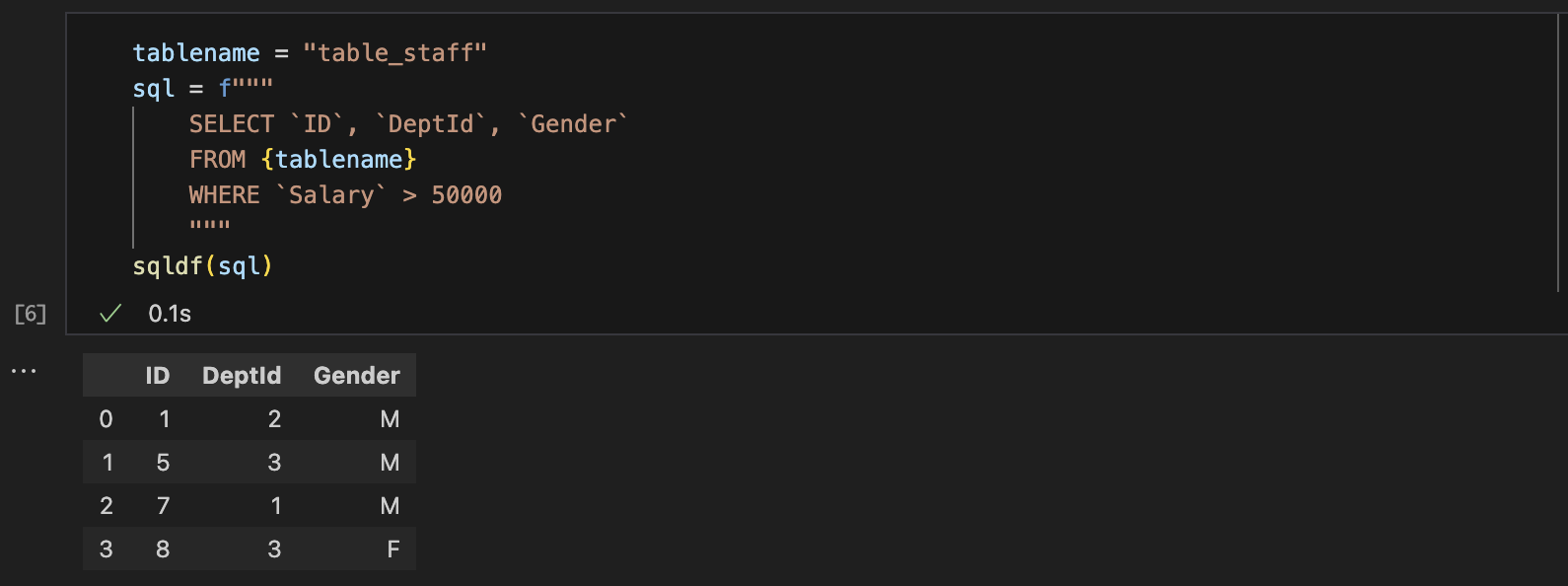
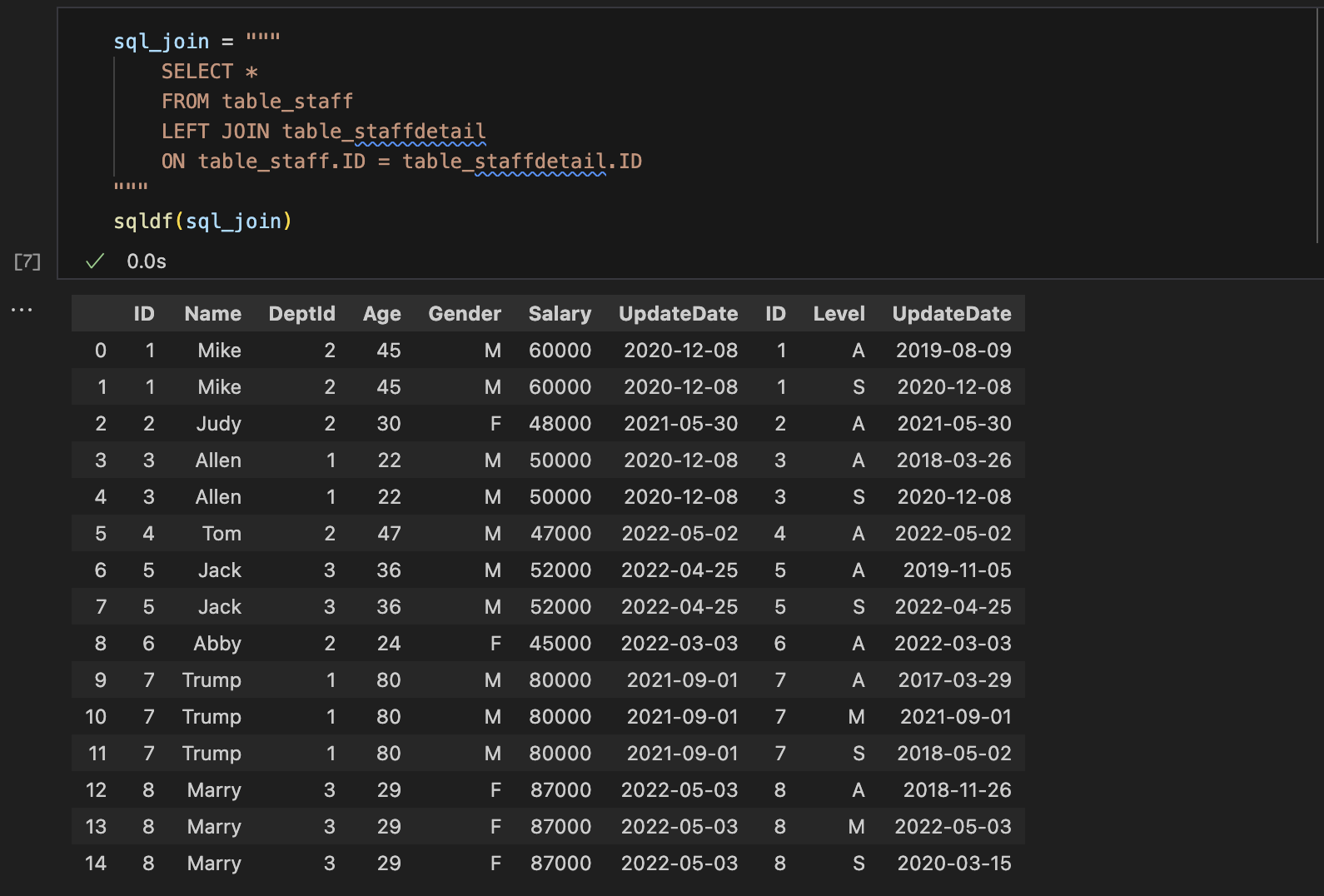
Execute SQL on DataFrame
Sample code
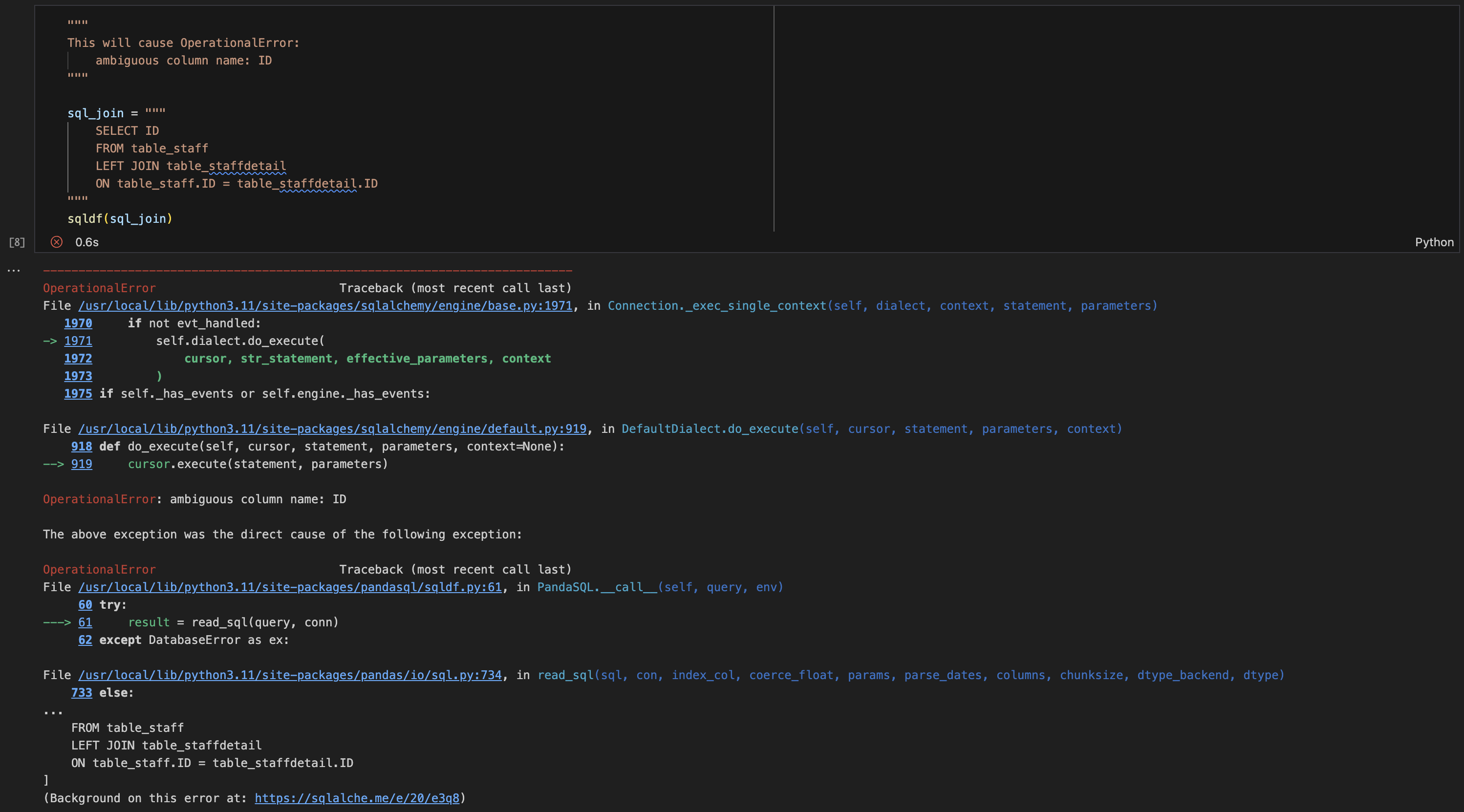
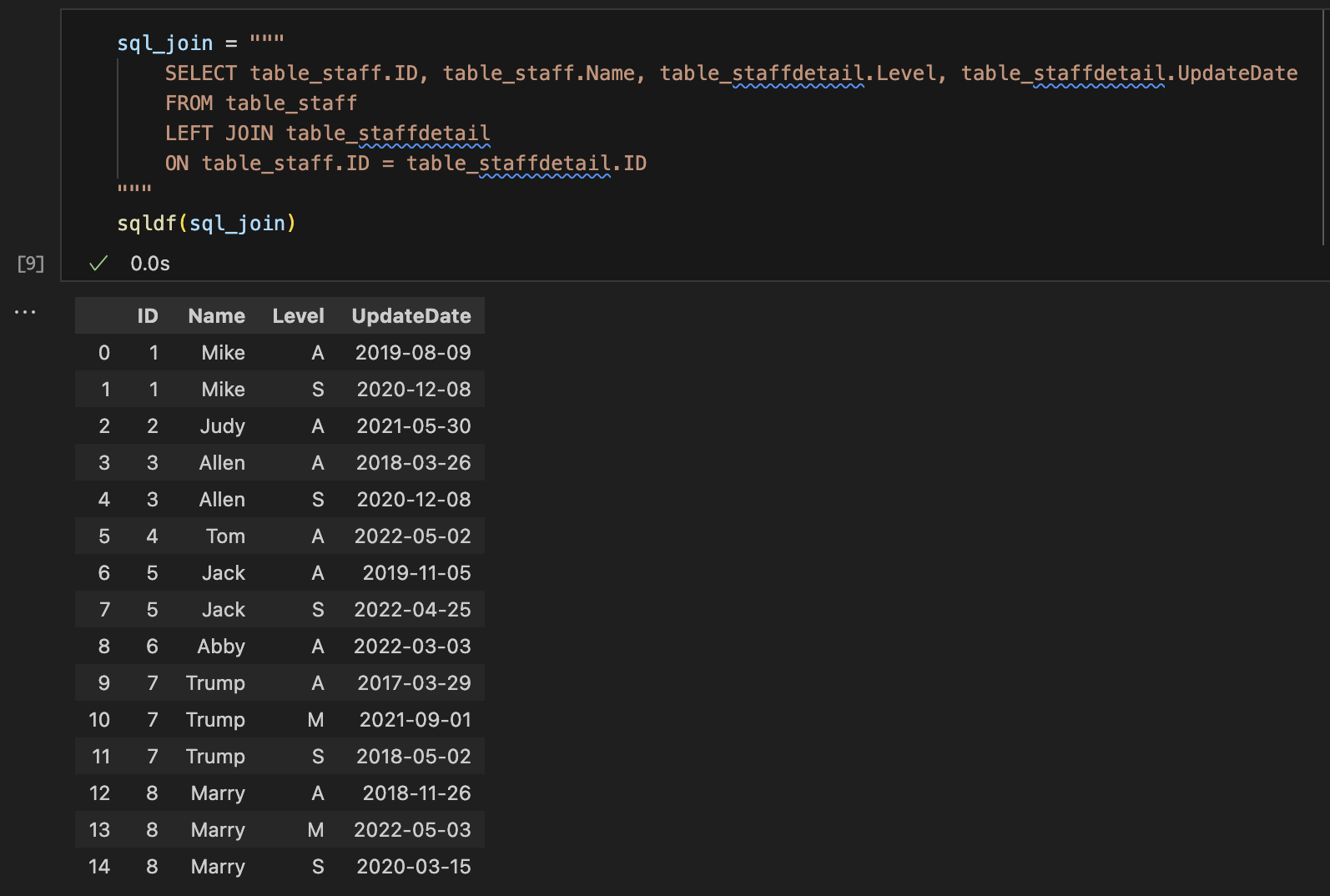
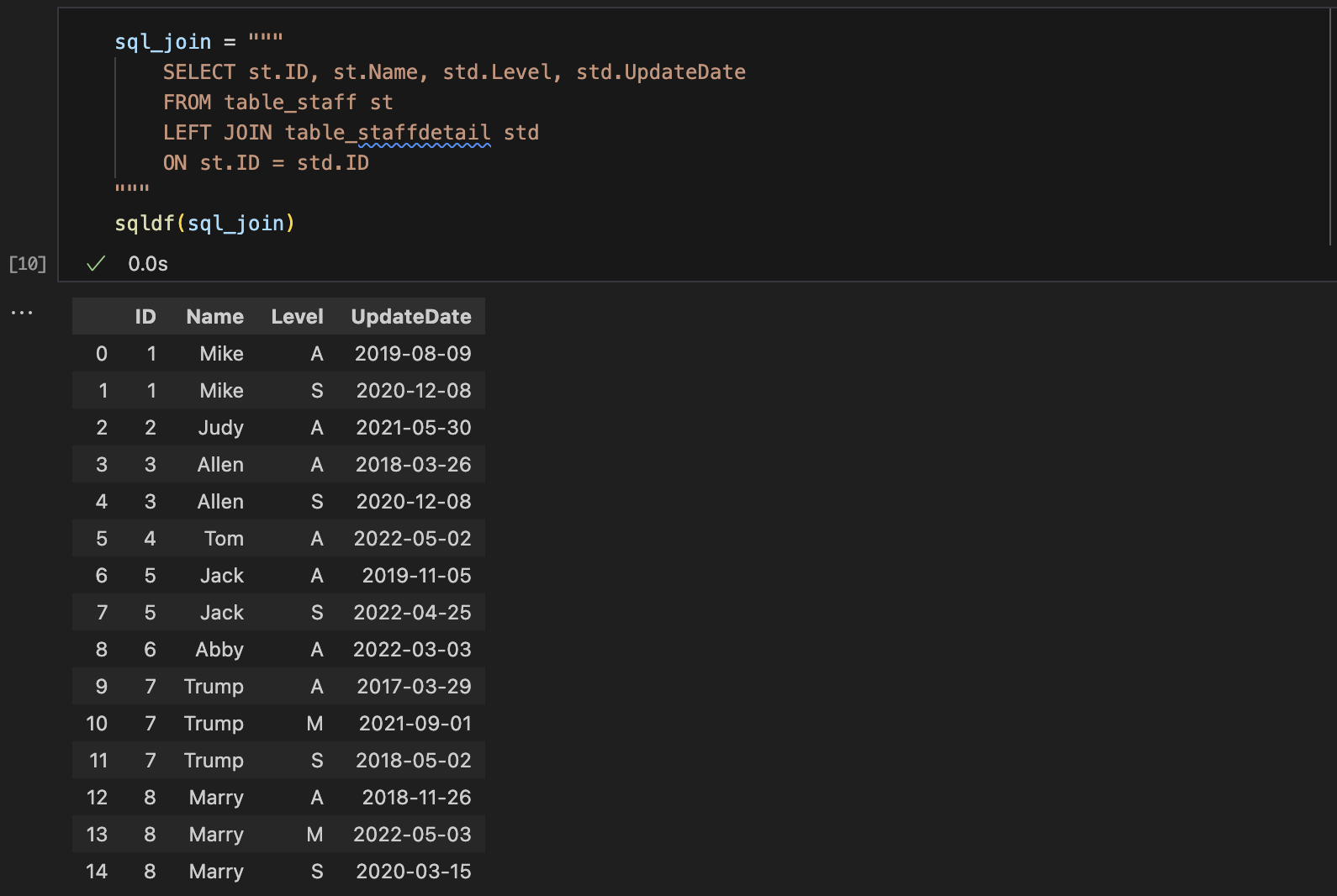
ROW_NUMBER()
Select the highest price of each author. All fields should be kept in the result table.
columns = ["article", "author", "price"]
data = [
["0001", "B", 3.99],
["0002", "A", 10.99],
["0003", "C", 1.69],
["0004", "B", 19.95],
["0005", "A", 6.96],
]
prticle_price_df = pd.DataFrame(data=data, columns=columns)
prticle_price_df
sql = """
with tmp_prticle_price_df as (
select
*,
ROW_NUMBER() OVER (PARTITION BY author ORDER BY price DESC) as ROW_ID
from prticle_price_df
)
select
article,
author,
price
from tmp_prticle_price_df
where ROW_ID = 1
"""
sqldf(
sql,
)